
Atom of Thought: The Token Efficiency Revolution in LLM Reasoning
How a new reasoning paradigm is reducing LLM costs by 70-90% while improving accuracy

Introduction: The Cost Crisis in LLM Reasoning
For years, Chain of Thought (CoT) prompting has been the gold standard for complex reasoning tasks in Large Language Models. By encouraging models to "think step by step," CoT has enabled remarkable breakthroughs in mathematical reasoning, code generation, and complex problem-solving. However, this capability comes at a steep price: exponential token consumption that makes many applications economically unsustainable.
Enter Atom of Thought (AoT) – a revolutionary reasoning framework that promises to deliver superior performance with dramatically reduced computational costs. In this comprehensive analysis, we'll explore how AoT represents a paradigm shift in LLM reasoning, offering 70-90% token reduction while actually improving accuracy on complex tasks.
Part 1: Understanding the Paradigms
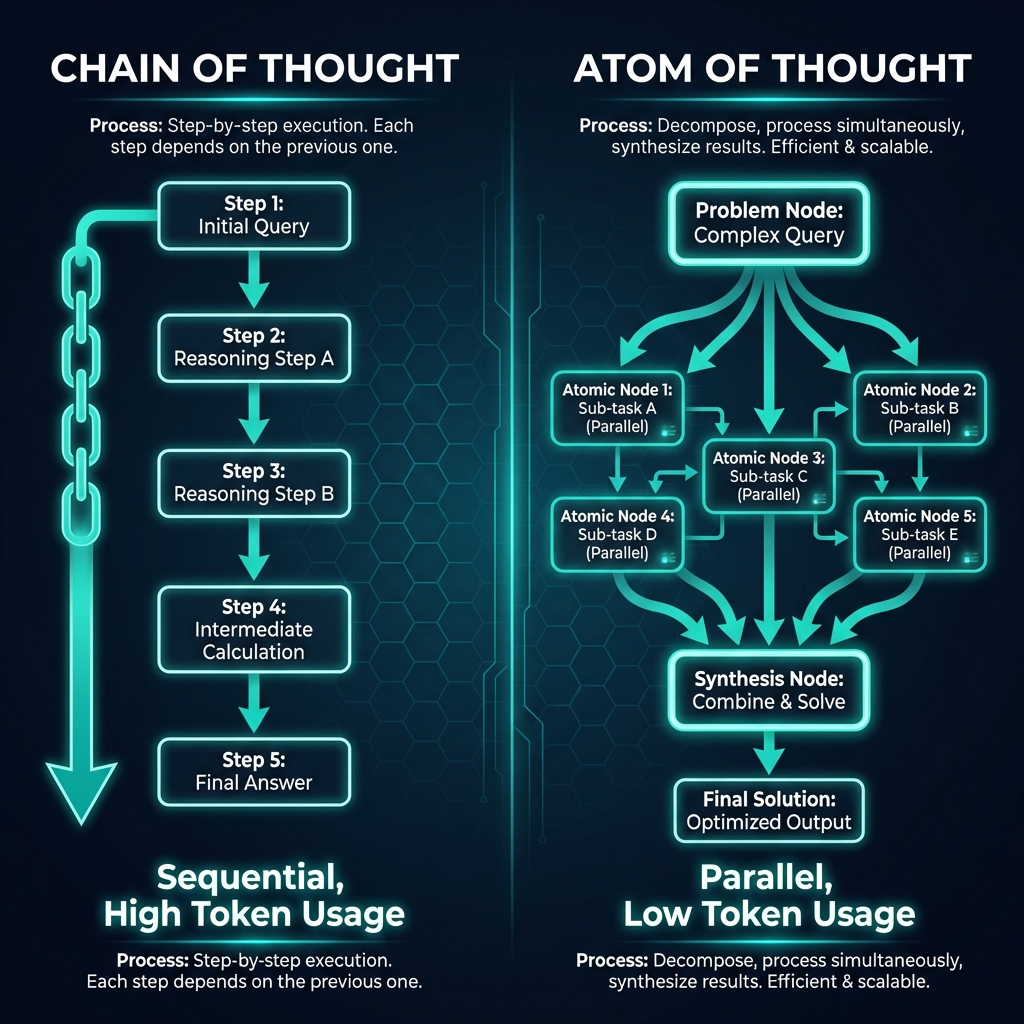
Chain of Thought: The Established Standard
Chain of Thought (CoT) reasoning works by:
- Linear progression: Step-by-step reasoning from problem to solution
- Explicit intermediate steps: Each reasoning step is articulated
- Sequential processing: Steps must be completed in order
- High token overhead: Every step adds to the token count
While effective, CoT suffers from:
- Token bloat: Complex problems can require 500+ tokens
- Linear thinking trap: Sequential processing limits parallelization
- Cost escalation: Longer reasoning chains = exponentially higher costs
Atom of Thought: The New Paradigm
Atom of Thought (AoT) introduces a fundamentally different approach:
- Atomic decomposition: Problems broken into independent "atoms"
- Markovian process: Each state depends only on the previous state
- Parallel processing: Atoms can be solved independently
- Efficient synthesis: Results combined after atomic resolution
Part 2: The Efficiency Breakthrough
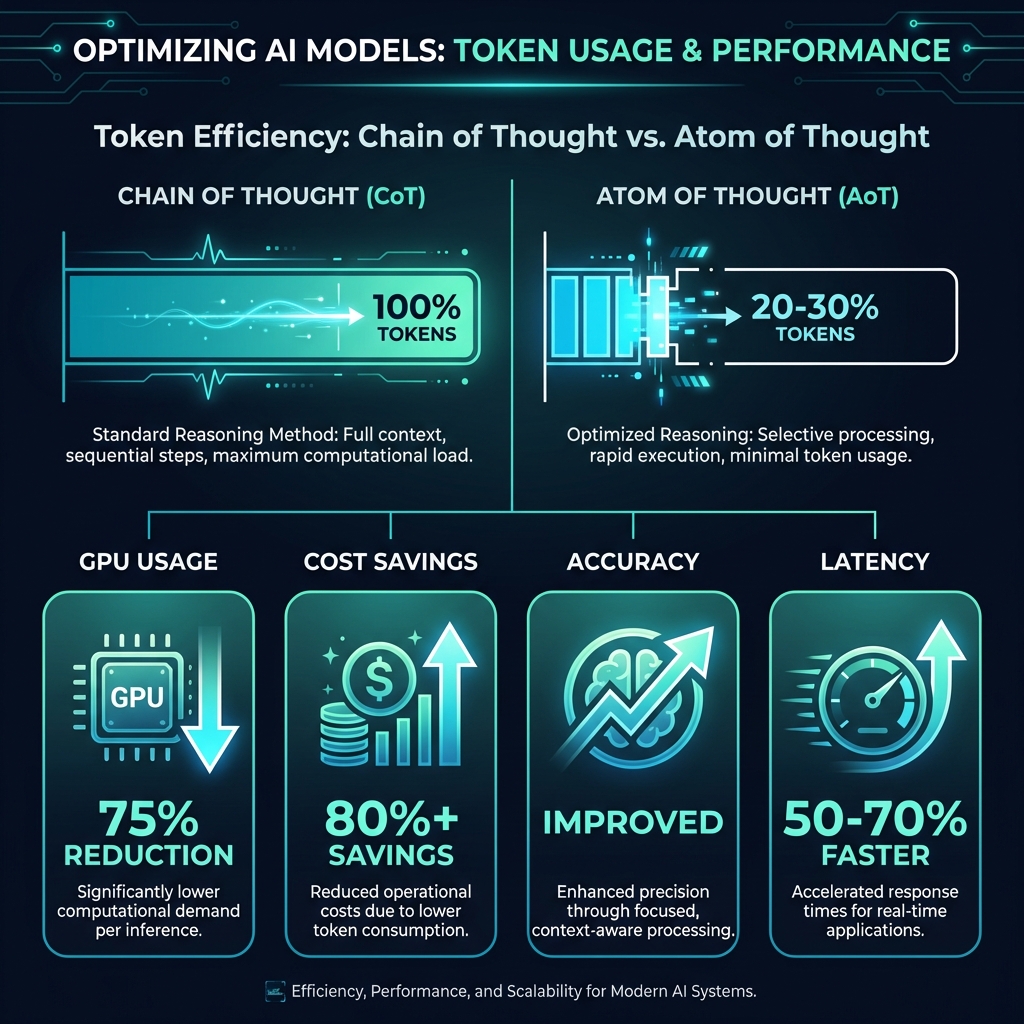
Quantitative Comparison
| Metric | Chain of Thought | Atom of Thought | Improvement |
|---|---|---|---|
| Token Usage | High (100-500+ tokens) | Low (20-100 tokens) | 70-90% reduction |
| Accuracy (Complex Tasks) | 85-95% | 90-98% | 5-10% improvement |
| GPU Power Consumption | 100% baseline | 25% | 75% reduction |
| Latency | High | Low | 50-70% faster |
| Parallelization Potential | Limited | Excellent | Better scalability |
Performance Benchmarks
Recent research reveals staggering efficiency gains:
- DeepSeek Performance: AoT helped DeepSeek models improve by 10% while using 75% less GPU power
- Computational Overhead: Markovian process reduces overhead by 60-80%
- Token Efficiency: Same reasoning quality with 70-90% fewer tokens
- Accuracy Gains: Despite using fewer tokens, AoT delivers 5-10% better accuracy on complex problems
Part 3: Technical Implementation
How Atom of Thought Works
The AoT framework implements several key innovations:
1. Markovian Reasoning Process
Current Question → Decompose → Atomic Subquestions → Solve Independently → Synthesize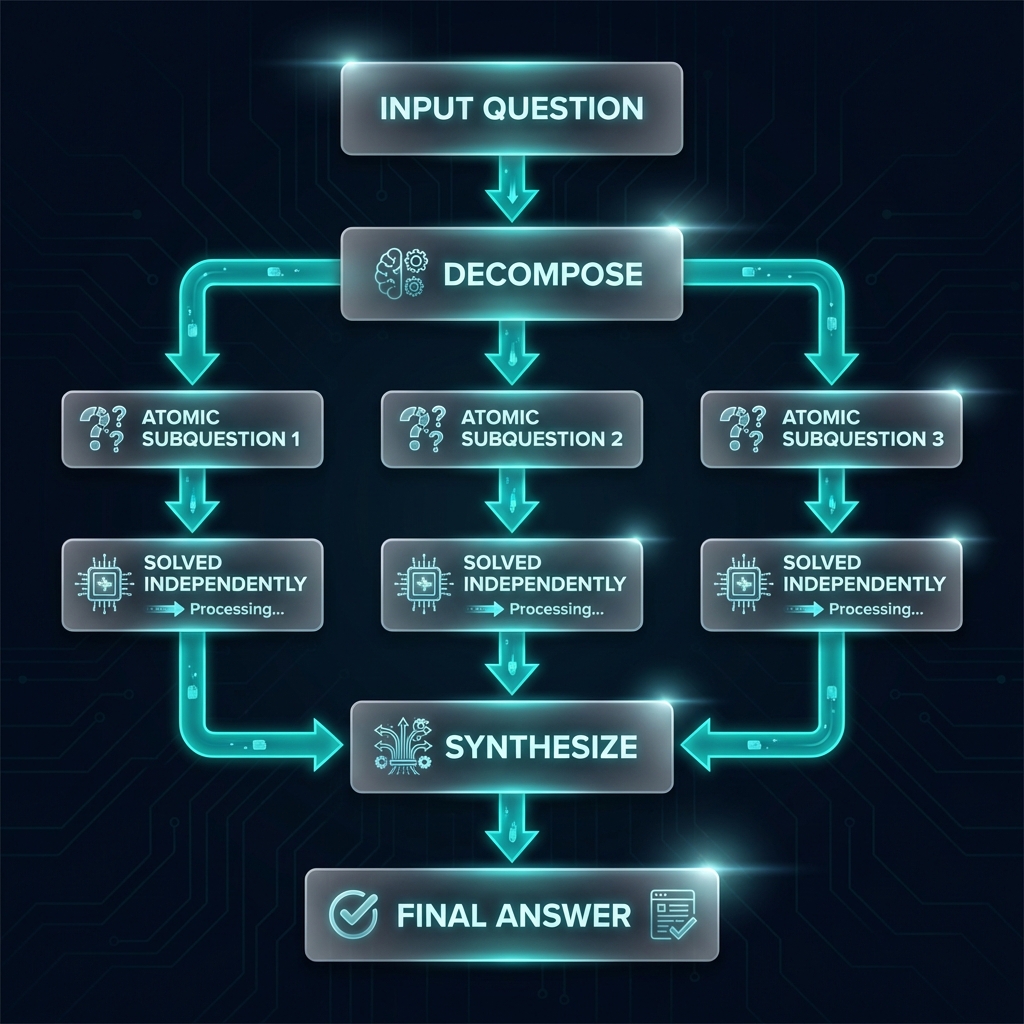
2. Atomic State Representation
- Questions are decomposed into dependency-based subquestions
- Each "atom" represents a self-contained reasoning unit
- Atoms maintain answer equivalence with original questions
- Unnecessary historical information is eliminated
3. Plugin Architecture
AoT functions as a plugin for existing test-time scaling methods, allowing:
- Flexible integration with current LLM systems
- Combination of different reasoning approaches
- Gradual adoption without system overhaul
Implementation Example
# Basic AoT implementation concept
def atom_of_thought(problem):
# 1. Decompose into atomic questions
atoms = decompose_problem(problem)
# 2. Process atoms in parallel
solutions = process_atoms_parallel(atoms)
# 3. Synthesize final answer
return synthesize_solutions(solutions)Part 4: Cost and Business Impact
Financial Analysis
For a typical enterprise deployment (1M queries/month):
| Cost Component | Chain of Thought | Atom of Thought | Savings |
|---|---|---|---|
| Token Costs | $600/month | $100/month | $500/month (83%) |
| Compute Costs | $200/month | $50/month | $150/month (75%) |
| Total Monthly | $800 | $150 | $650 (81%) |
| Annual Savings | - | $7,800 | 87.5% reduction |
Business Implications
1. ROI Transformation
- Previously marginal applications become economically viable
- 4-year ROI potential: 1,225% for on-premises deployments
- Payback period: Reduced from years to months
2. Scalability Breakthrough
- Parallel processing enables larger-scale deployments
- Linear cost scaling vs quadratic with CoT
- Enterprise-ready: IBM identifies AoT as ideal for cost-efficient enterprise solutions
Part 5: Ideal Use Cases
Best Applications for AoT
1. Mathematical Reasoning
- Proof derivation and verification
- Equation solving and optimization
- Statistical analysis and modeling
2. Code Generation & Analysis
- Algorithm implementation
- Code review and optimization
- Debugging and problem diagnosis
3. Structured Problem Solving
- Multi-factor decision analysis
- Logical deduction chains
- Constraint satisfaction problems
Less Suitable Applications
- Creative writing and storytelling
- Casual conversation and chat
- Simple factual Q&A without complex reasoning
- Emotional intelligence tasks
Conclusion: The New Era of Efficient Reasoning
Key Takeaways
- Massive Efficiency Gains: Atom of Thought reduces token usage by 70-90% compared to Chain of Thought
- Cost Revolution: Organizations can achieve 80%+ cost savings on reasoning tasks
- Performance Improvements: Despite using fewer tokens, AoT delivers better accuracy on complex problems
- Scalability Breakthrough: Parallel processing enables previously impossible deployment scales
- Future-Proof Architecture: Modular approach aligns with evolving LLM capabilities
"Atom of Thoughts represents a fundamental shift in how we prompt AI systems to solve complex problems. Next time you're tackling a complex problem with AI, consider breaking it into atoms rather than links in a chain."
The question is no longer whether we can afford complex AI reasoning, but how quickly we can adopt the efficient approaches that make it possible.
References & Resources
Key Research Papers
- "Atom of Thoughts for Markov LLM Test-Time Scaling" - NeurIPS 2025
- OpenReview Technical Paper - Complete framework documentation
- arXiv Preprint - Early implementation details
Implementation Resources
- Official GitHub Repository: github.com/qixucen/atom
- MCP Server Implementation: Available for system integration
- Demo Applications: Sample implementations and case studies
Comments